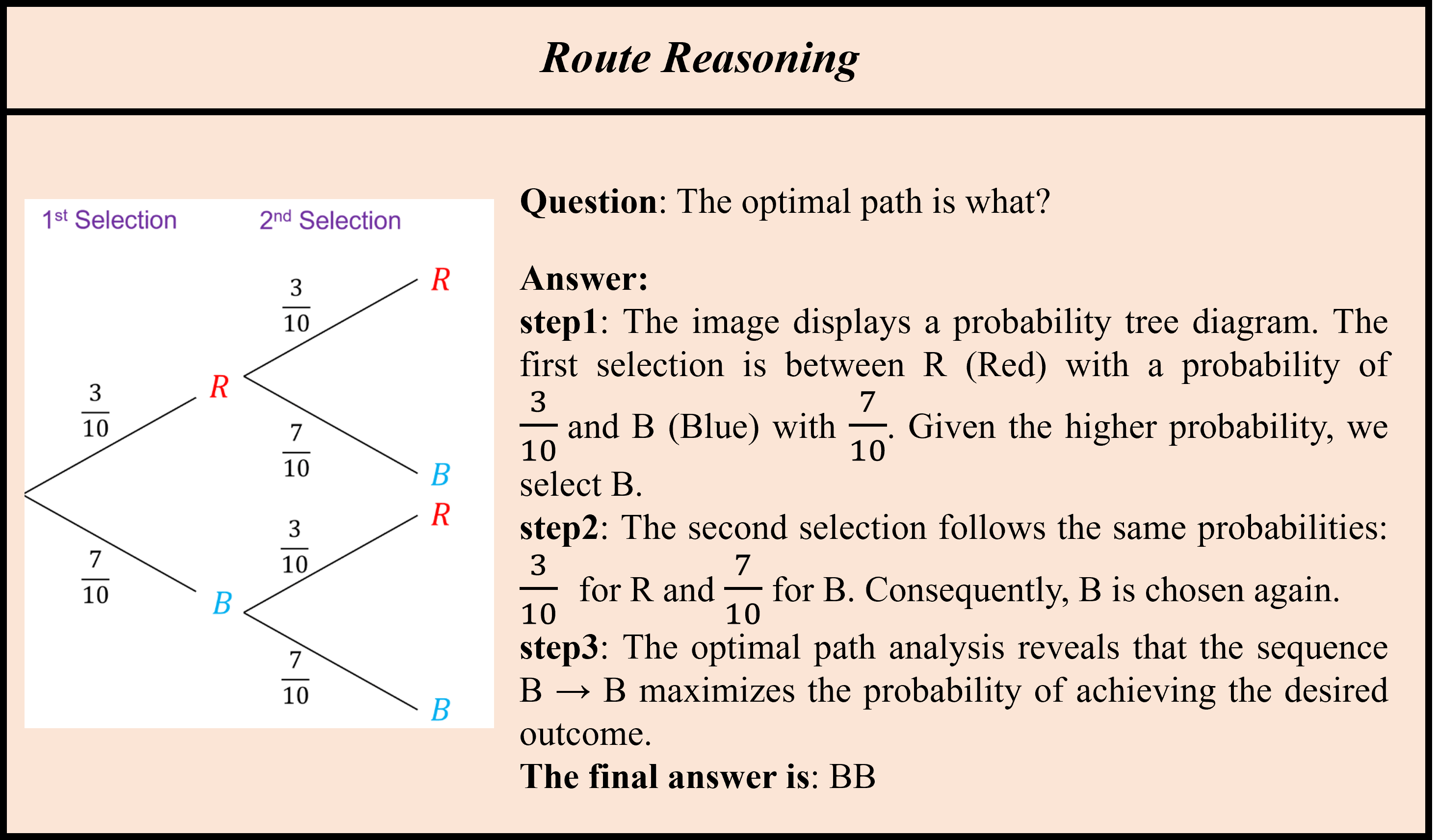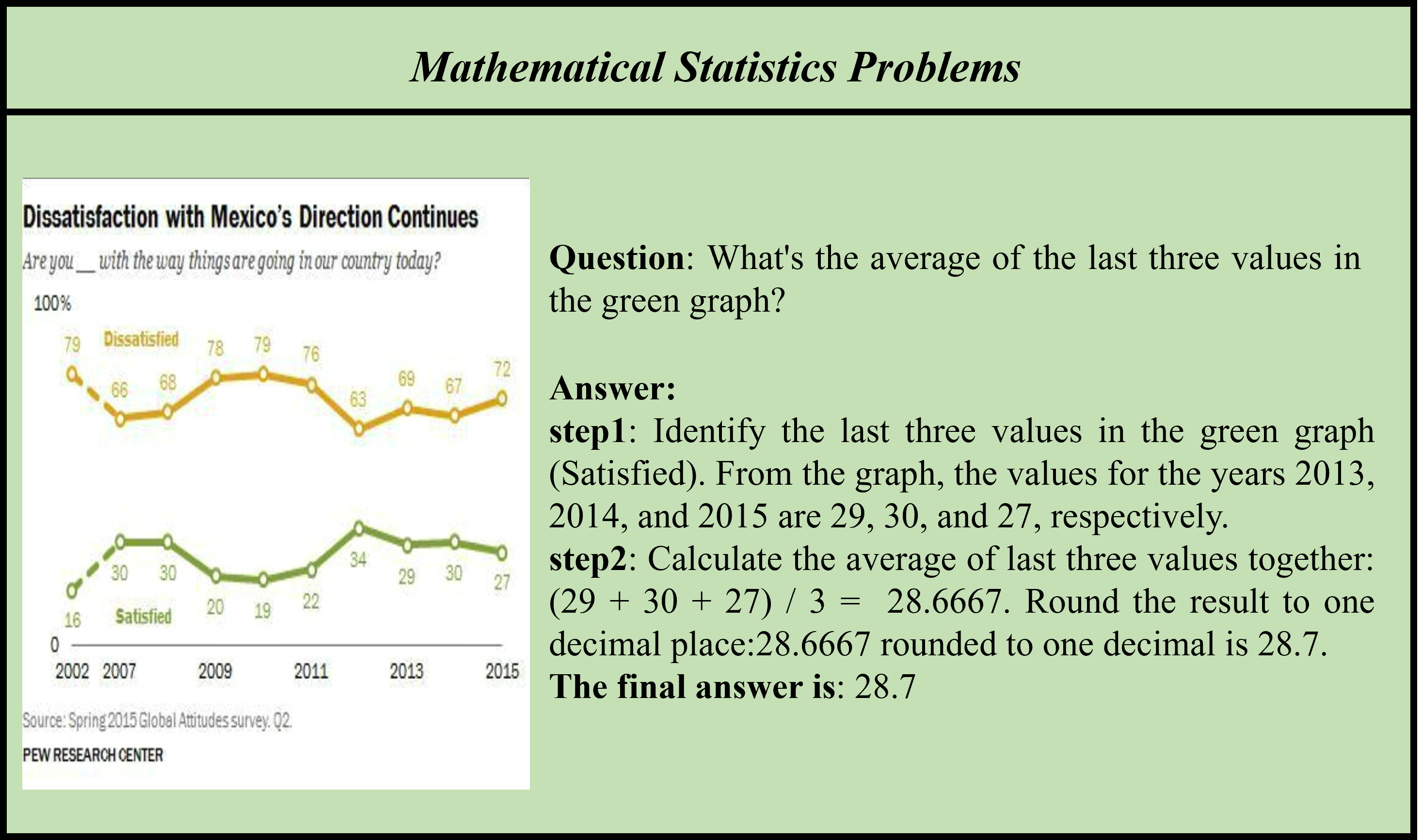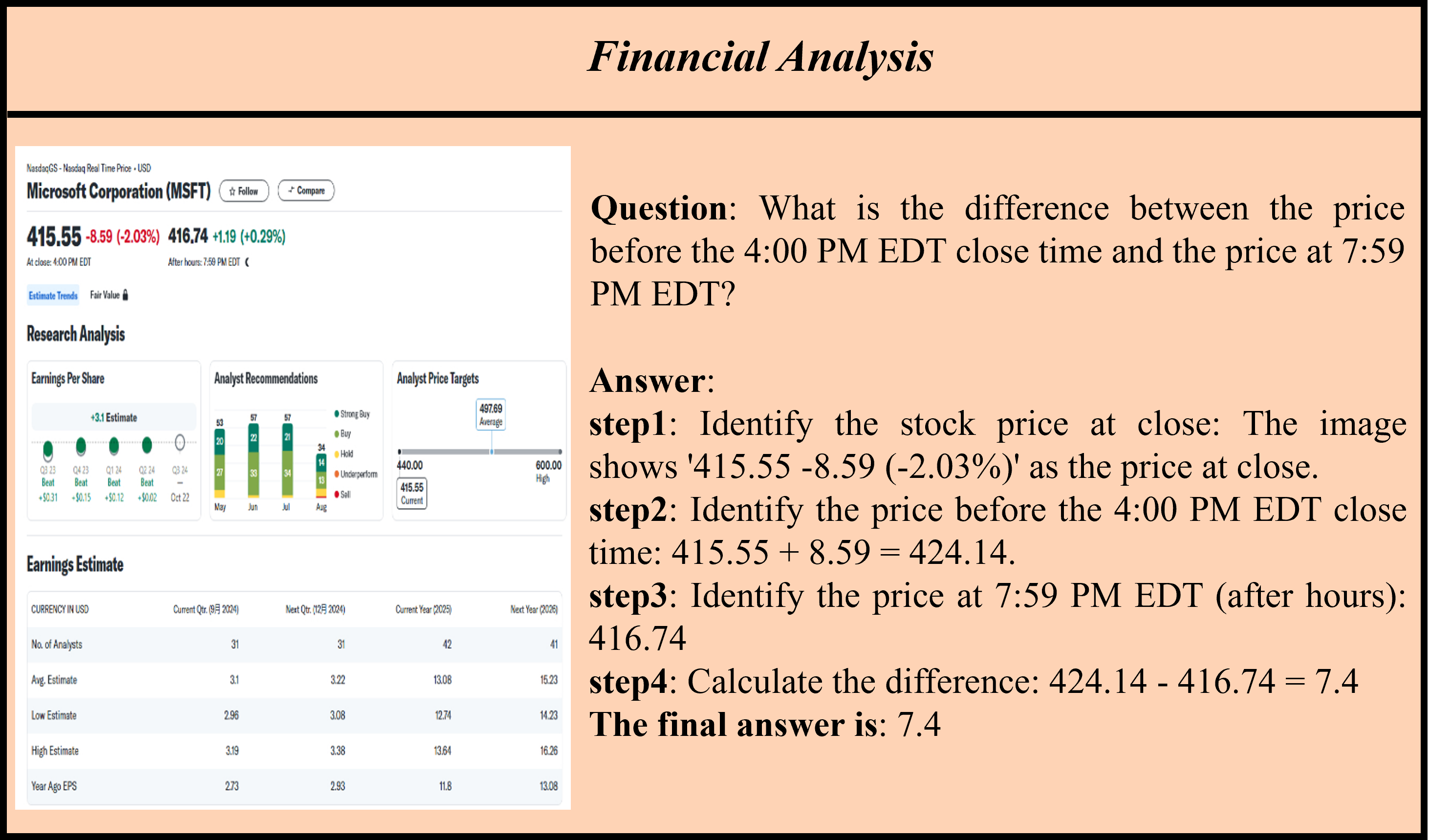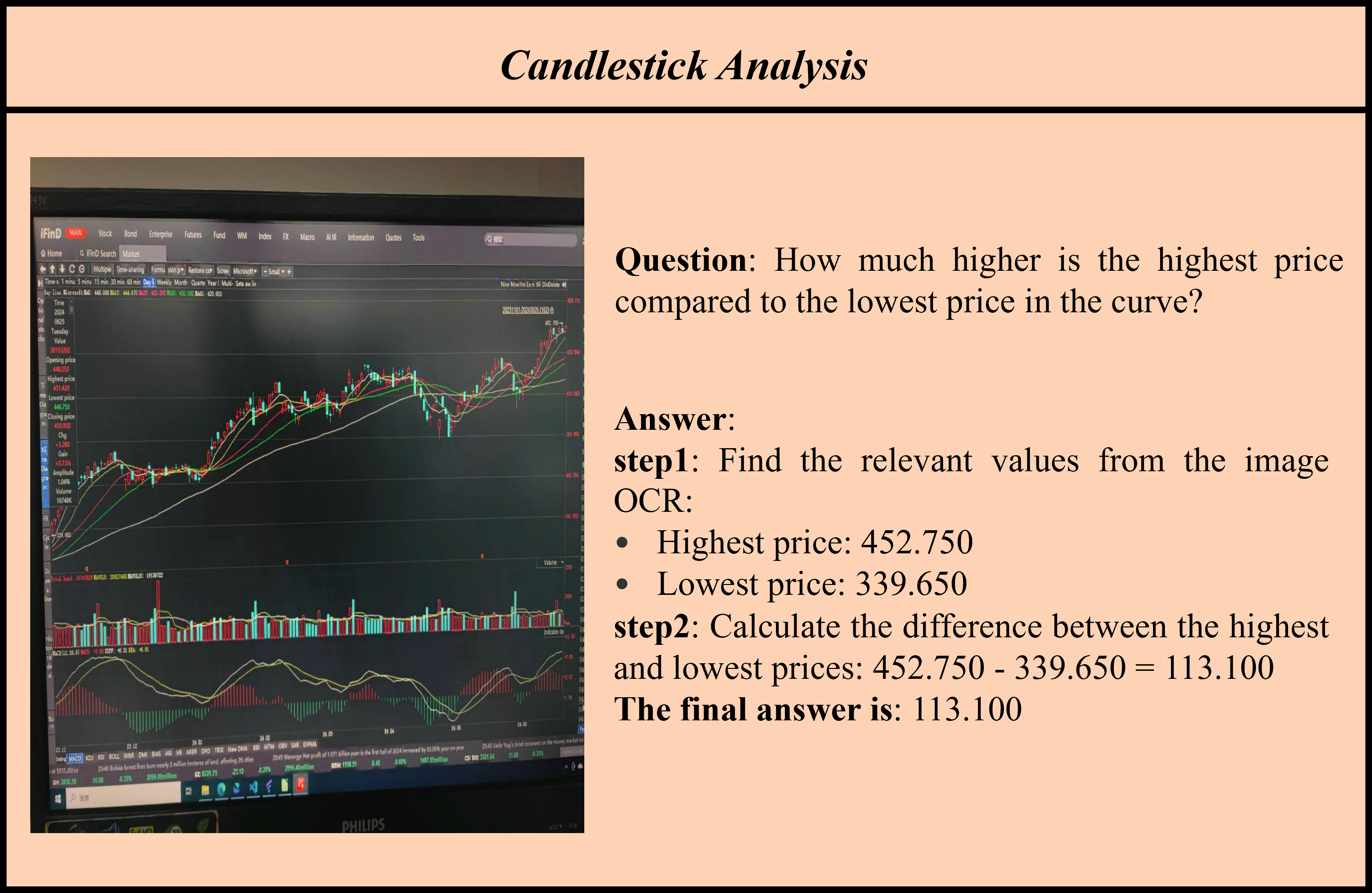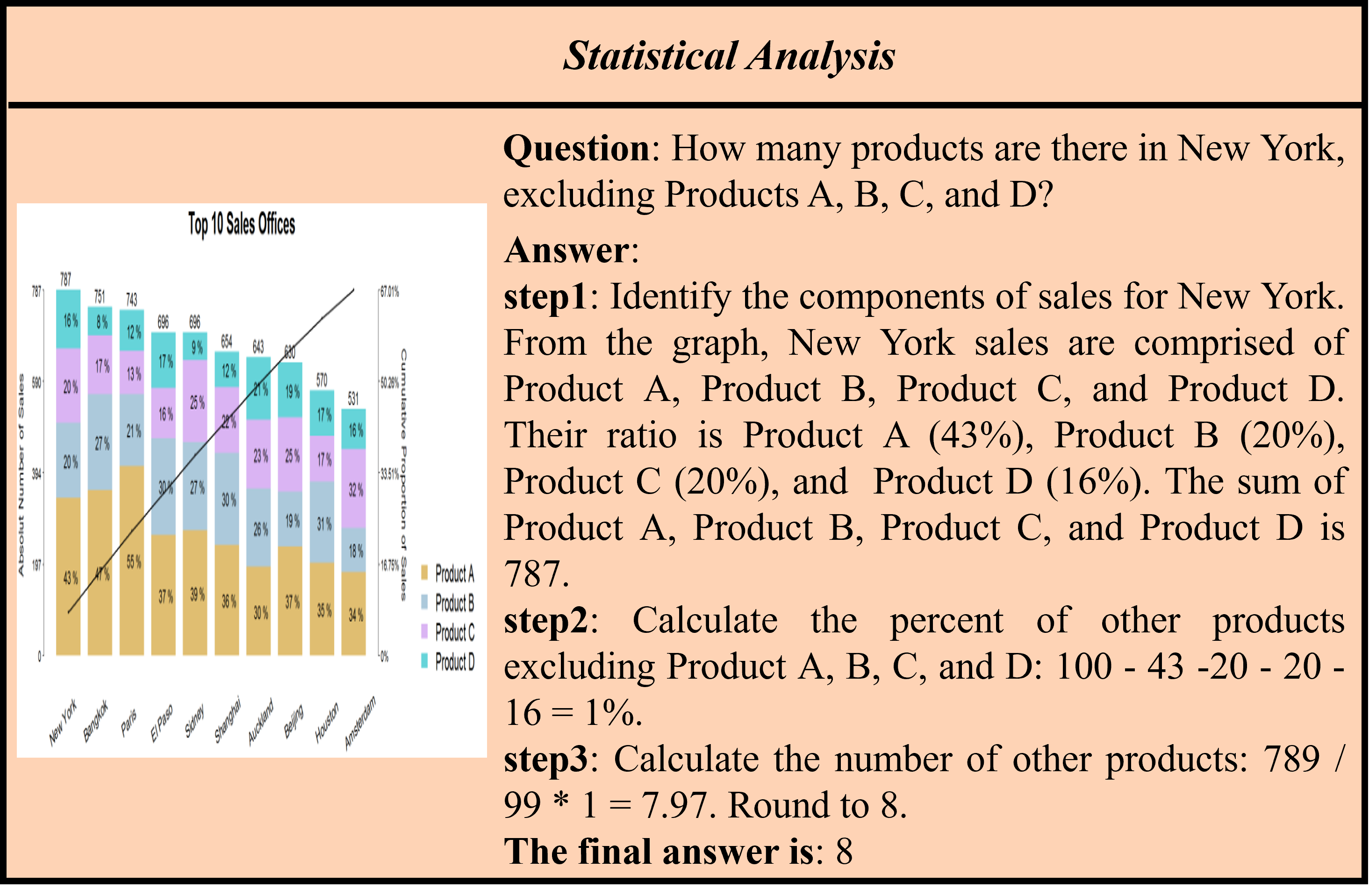
Accuracy scores on the test subset (1069 examples) of ![]() OCR-Reasoning.
OCR-Reasoning.
| # | Model | Method | Source | Date | ALL | SR | NAR | MR | ER | LR | MKR |
| 1 | DouBao-1.5-Vision-Pro 🥇 | MLLM 🖼️ | Link | 2025-05-22 | 46.8 | 27.5 | 54.0 | 33.3 | 50.8 | 34.7 | 58.4 |
| 2 | OpenAI-o1 🥈 | MLLM 🖼️ | Link | 2025-05-22 | 44.4 | 27.5 | 46.2 | 43.1 | 50.8 | 40.3 | 49.6 |
| 3 | Gemini-2.0-Flash 🥉 | MLLM 🖼️ | Link | 2025-05-22 | 39.3 | 19.3 | 47.2 | 24.5 | 49.7 | 36.8 | 32.1 |
| 4 | Qwen2.5-VL-72B | MLLM 🖼️ | Link | 2025-05-22 | 37.5 | 24.8 | 44.7 | 22.5 | 47.5 | 28.5 | 34.3 |
| 5 | Qwen2.5-VL-32B | MLLM 🖼️ | Link | 2025-05-22 | 36.2 | 21.1 | 38.7 | 25.5 | 46.9 | 34.7 | 36.5 |
| 6 | Claude-3.7-Sonnet | MLLM 🖼️ | Link | 2025-05-22 | 35.8 | 20.2 | 35.4 | 23.5 | 60.3 | 30.6 | 32.1 |
| 7 | OpenAI-o3-mini | Tool 🛠️ | Link | 2025-05-22 | 33.3 | 17.4 | 41.2 | 25.5 | 41.3 | 24.3 | 27.7 |
| 8 | GPT-4o | MLLM 🖼️ | Link | 2025-05-22 | 30.7 | 21.1 | 35.9 | 18.6 | 40.8 | 26.4 | 23.4 |
| 9 | Llama4-Scout-109B-A17B | MoE 🤖 | Link | 2025-05-22 | 27.7 | 15.6 | 34.7 | 16.7 | 41.3 | 22.9 | 12.4 |
| 10 | DeepSeek-R1-Distill-Qwen-32B | Tool 🛠️ | Link | 2025-05-22 | 26.5 | 11.9 | 28.9 | 23.5 | 34.6 | 18.8 | 30.7 |
| 11 | Kimi-VL-A3B-Thinking | MoE 🤖 | Link | 2025-05-22 | 20.5 | 11.9 | 22.4 | 14.7 | 24.6 | 21.5 | 19.7 |
| 12 | InternVL3-78B | MLLM 🖼️ | Link | 2025-05-22 | 19.9 | 13.8 | 22.4 | 9.8 | 14.0 | 27.1 | 25.5 |
| 13 | InternVL3-32B | MLLM 🖼️ | Link | 2025-05-22 | 17.1 | 14.7 | 10.3 | 14.7 | 24.0 | 11.8 | 37.2 |
| 14 | Qwen2.5-VL-7B | MLLM 🖼️ | Link | 2025-05-22 | 15.7 | 13.8 | 11.6 | 8.8 | 20.1 | 9.0 | 35.8 |
| 15 | VL-Rethinker-7B | MLLM 🖼️ | Link | 2025-05-22 | 14.6 | 8.3 | 16.1 | 9.8 | 19.6 | 8.3 | 19.0 |
| 16 | VLAA-Thinker-Qwen2.5VL-7B | MLLM 🖼️ | Link | 2025-05-22 | 14.4 | 11.9 | 10.3 | 7.8 | 21.2 | 11.8 | 27.0 |
| 17 | MM-Eureka-Qwen-7B | MLLM 🖼️ | Link | 2025-05-22 | 13.2 | 9.2 | 7.0 | 10.8 | 18.4 | 15.3 | 27.0 |
| 18 | Qwen2.5-VL-3B | MLLM 🖼️ | Link | 2025-05-22 | 12.2 | 11.0 | 11.8 | 9.8 | 19.0 | 7.6 | 11.7 |
| 19 | InternVL3-8B | MLLM 🖼️ | Link | 2025-05-22 | 11.5 | 12.8 | 5.8 | 11.8 | 17.9 | 7.6 | 22.6 |
| 20 | InternVL3-2B | MLLM 🖼️ | Link | 2025-05-22 | 10.8 | 11.9 | 4.8 | 7.8 | 18.4 | 11.8 | 18.3 |
Task types: SR: Spatial Reasoning, NAR: Numerical Analysis Reasoning, MR: Mathematical Reasoning, ER: Enumerative Reasoning, LR: Logical Reasoning, MKR: Multidisciplinary Knowledge Reasoning